Like many people in the field of 3D graphics, I’ve been following along with the saga of Euclideon’s Unlimited Detail technology for a while now
(If you don’t know about it then go watch this, this, and this) And a few weeks ago they released the following footage:
Which got me thinking again about what their technology might be. The general consensus online seems to be that they have created some sort of voxel render engine that stores data in sparse voxel oct trees. Folks seem to be polarized between believing (Even evangelizing) the word of Euclideon’s CEO, Bruce Dell that the technology will render [pun] the current polygon-based industry irrelevant overnight – and those that believe it is either a complete scam, overhyped marketing, and/or just an impossible or broken idea altogether.
So I thought I would put aside the comments and opinions and have a bit of a think about what could be going on. I should make clear upfront that I am not a ‘hardcore programmer’ by any stretch of the imagination. I have done some programming and scripting as part of my job as a Technical Director but if anything I like to think I sit more on the content creation and artistic side of the fence than the code side.
The first step for me was to do some reading up on some of the tech people are proposing it could be – starting with visiting the wonderful world of Oct Trees and some ideas of how they can be used (Note: I had researched oct trees and a bunch of other volume partitioning methods way back in 2000 / 2001 when working on some ideas for compressing 3D data for transmission over the internet with some guys I was working with. Unfortunately, that didn’t pan out but I still think about a lot of the ideas I was coming up with)
Most of the information about oct trees seemed to be fairly focused on using them to accelerate ray tracing and ray marching rendering (Eg Check out the amazing Gigavoxels!) One of the great advantages of oct trees is the data is embedded within the structure – meaning you don’t have to keep track of where in 3D space a particular point is because the way it is stored within the tree handles that — so this got me thinking about if that same structure and data could also be used directly for rendering? This is what I came up with:
See the trees
Let’s take a step back from oct trees for a moment and break down the concept with a much simpler quadtree. So if we start with a 2D square area …

… if we find the centre point then we can divide this area into 4 equally sized and proportional sub-areas …
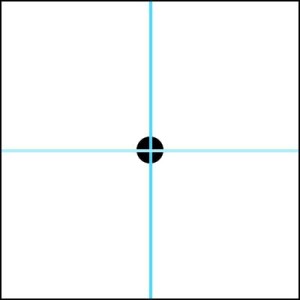
We can then begin to repeat the process with these 4 sub-areas by finding their centres…
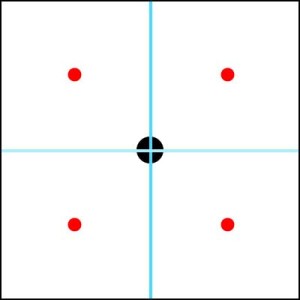
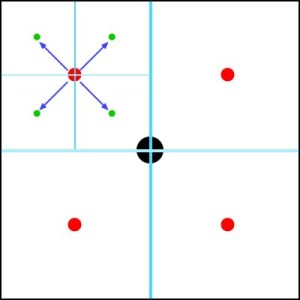
… but before subdividing these areas again, we find the 4 vectors which describe where the new centres are (4 directional vectors coming from the parent centre with a magnitude (Eg NOT unit vectors!))
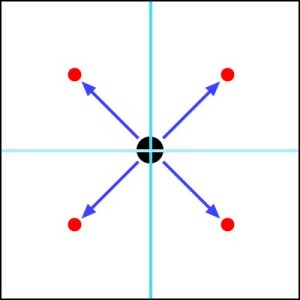
Now if we simply half the magnitudes of the vectors and offset them to the new centres then we can quickly and easily find the next level of division…
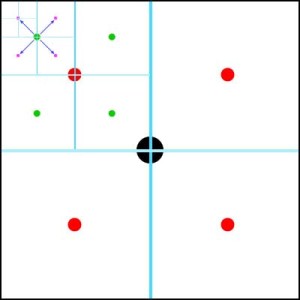
… and again halve and offset…
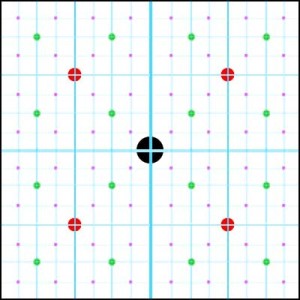
… we can keep doing this until we reach a point where the vector lengths cover less than a pixel. If we were to recurse through all the centres down to the 3rd level it would look like this…
This is all good and well for filling in a 2D square area but the same idea of creating 4 screen-based pattern vectors and halving and offsetting them also works in an orthographic 2D area and the process can be applied to an orthographic 3D space like these 3 orthographic planes …
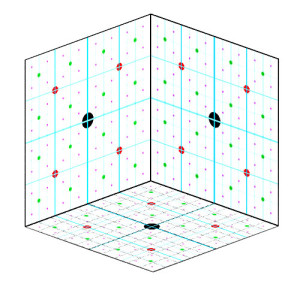
So visualizing the orthographic 3D centre points we can now build an 8 vector pattern to recurse through 3D orthographic space …
I did go one step further and try and apply this to perspective screen space but couldn’t quite get my mind around it to get it to work at the time (See “More ideas” below) So instead I went back to the above orthographic space and simply opted to do the perspective scaling when drawing the points on the screen.
Data
Another aspect that people talked a lot about was the data size problem when dealing with points and voxels. Again, instead of just taking the word of others I decided to do a bit of digging into this and came up with the following data structure for the oct tree (Note: There are a few different established ways already for oct tree data structures depending on what you want to use the oct tree for. I just picked the data I needed)
My ‘volume’ data looks like this…
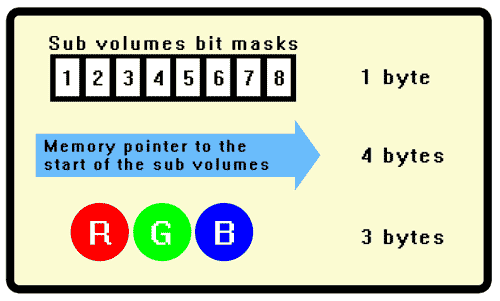
… and basically works by the 8 bits in the ‘Sub volumes bit mask’ indicates which of the 8 subvolumes have data (Eg Empty subvolumes are 0 and subvolumes with data are 1) Then there is the 4-byte pointer which points to a memory address where the sub volume data BEGINS. Then 3 bytes are used to describe the colour (Red, green, and blue) of this volume (Basically this is a pre-processed average of the colours of subvolume colours)
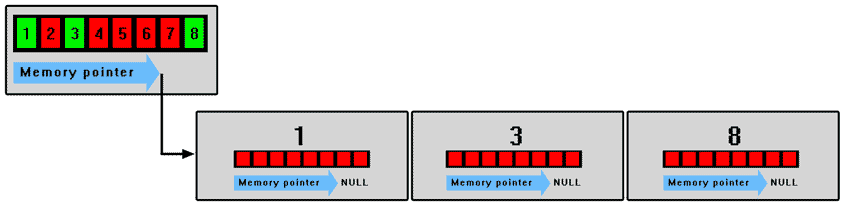
A single volume with 8 subvolumes (3 of which are NOT empty) would look something like this…
Let the coding begin
With the ideas above floating around in my mind, I started coding …
[ Insert sound of much key pressing here]
The pipeline I have set up at the moment has me creating and exporting polygon data from 3ds Max via Wavefront OBJ then running that through a hastily put together converter that sorts all the vertices recursively into the above volume structure. I can then load them into my engine (I’m cheekily calling my engine BladeEngine – because it slices through the volumes like a ninja! )
So with an actual engine I can now start doing some tests to see 1) how many volumes/points are really needed to see something interesting on screen 2) how big is data really going to be 3) can it run at interactive speeds? The first test is a simple cube been subdivided …

… already I’m seeing I need more than 240,000 points to get anywhere near a solid model on screen – and that is at the screen size above! :S … The good news from this test was even with 240,000 points it was running at a decent speed (And much like the Euclideon demo, it is only using 1 core and not touching the graphics card)
The next test was trying out a sphere (Amazing 3D skillz!) …
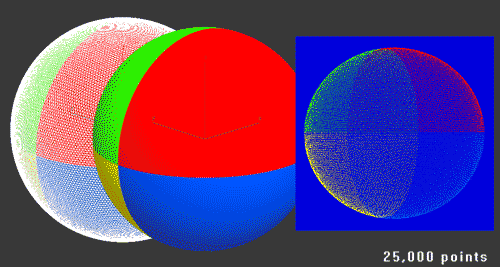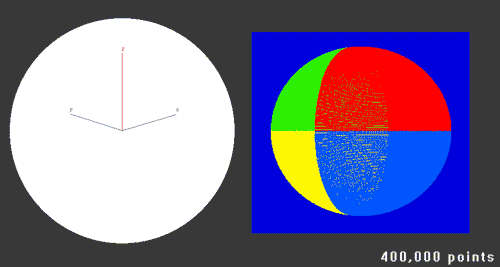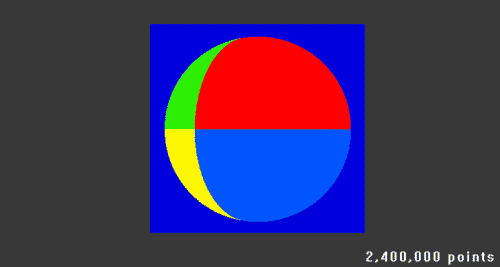
… this time it took pushing it up to 2.4 million points to get enough detail to fill in most of the holes at that screen size. I also added the ability to bake the texture colours into the volumes. I am seeing slow down when getting up close to these volumes now but at a medium-size on screen and further away works fine.
At this point, I got bored with looking at boxes and spheres so I grabbed a head model from the Afterdeath project I am currently working on. This was also to gauge how a ‘real world’ model might fare…

Starting with a 35,000 point version I had to divide it all the way up to 2.2 million points before it would draw filled in at a decent size. Again, the texture is embedded into the volumes – this time with some baked lighting as well.
The main problem I still have is if you get close to the model then you start seeing the individual, underlying points …

… there seem to be 3 potential fixes for this
1) render more data/points
2) draw the volumes bigger when you get close
3) do a post-render trick to fill in the holes.
While testing I did try out number 2 – drawing volumes bigger when you get closer, and it did work pretty well … except for the big performance hit. I would expect that number 3 – the post-render trick to fill in gaps would also cause the frame rate to suffer. Which at this point just leaves number 1 – render more data … but considering this ~2.2 million point model turns into a ~4 million volume oct tree that uses up around 33Meg for all its data, it may not be a viable option.
So in short, data size may be a problem – but then again perhaps not as much as I think when compared to polygons. Or at least in the way that polygons seem to be moving towards more dense meshes and higher resolution textures.
Just on a side note, although the above head model is using around 33Meg of memory when loaded into the engine, as data stored on disk it only requires half that amount (4 bytes per volume) simply because I calculate the 4-byte pointer only when loading the volume data.
Anyway, moving on, the next test was to have lots and lots of objects on the screen. All the volume data for the model is encapsulated within an ‘object’. Besides the volume data, the object can also have a bunch of other properties associated with it. For example, the objects I made have positional, rotation, and size information, meaning I can make many objects, all with unique locations, orientations, and scales (Only uniform scale for now) Here are 101 uniquely located and rotated objects all referencing the same volume data …

… and a little video moving around them (Yes, it is creepy when I fly through their heads and they dissolve into points )
More ideas
So a few ideas for further investigation:
– Screen space patterns … if I can actually figure this out it should speed things up noticeably.
– 64 volumes … move from the traditional 2x2x2 oct tree volume to a 4x4x4 volume. This can save data space (Well at least for the colour information) and potentially speed things up by doing more per volume before recursing.
– Backface culling … this is something I experimented with near the beginning but then newer code broke it ;P Basically using 6 bits of 1 byte per volume to indicate which direction(s) a volume is facing and not recursing into a volume if it is facing away from the camera. In my initial tests this generally worked well but if used again would break the nice 8-byte memory alignment I currently have plus add 1 more byte per volume (It all adds up!)
– Occlusion culling … one of the biggest rendering problems with any non-ray tracing/casting engine is usually overdraw. Need to think about possibilities here.
– Multithreading … I did do a quick multi-thread test in an early version and it did work pretty well. Two threads do not double the speed but it does make a big impact. Plus it is a system that can be multi-threading in many different areas!
– Graphics card … probably should look into CUDA and/or OpenCL. Just like multi-threading, there is a heap of things that could be run in parallel here I think.